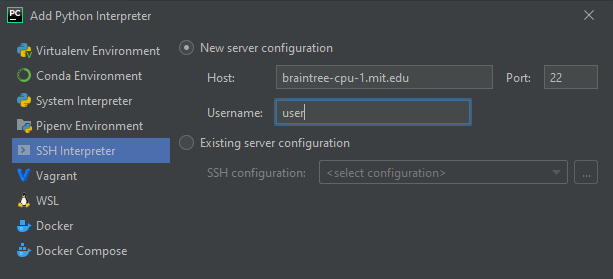
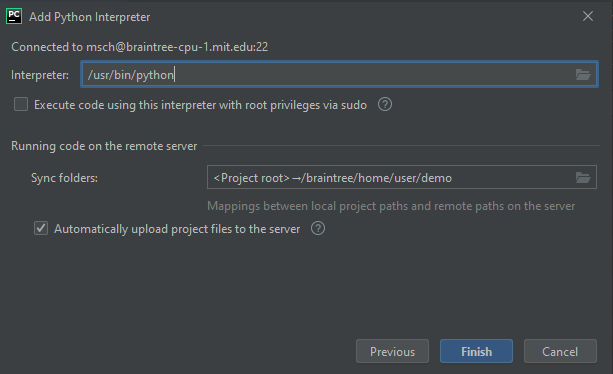
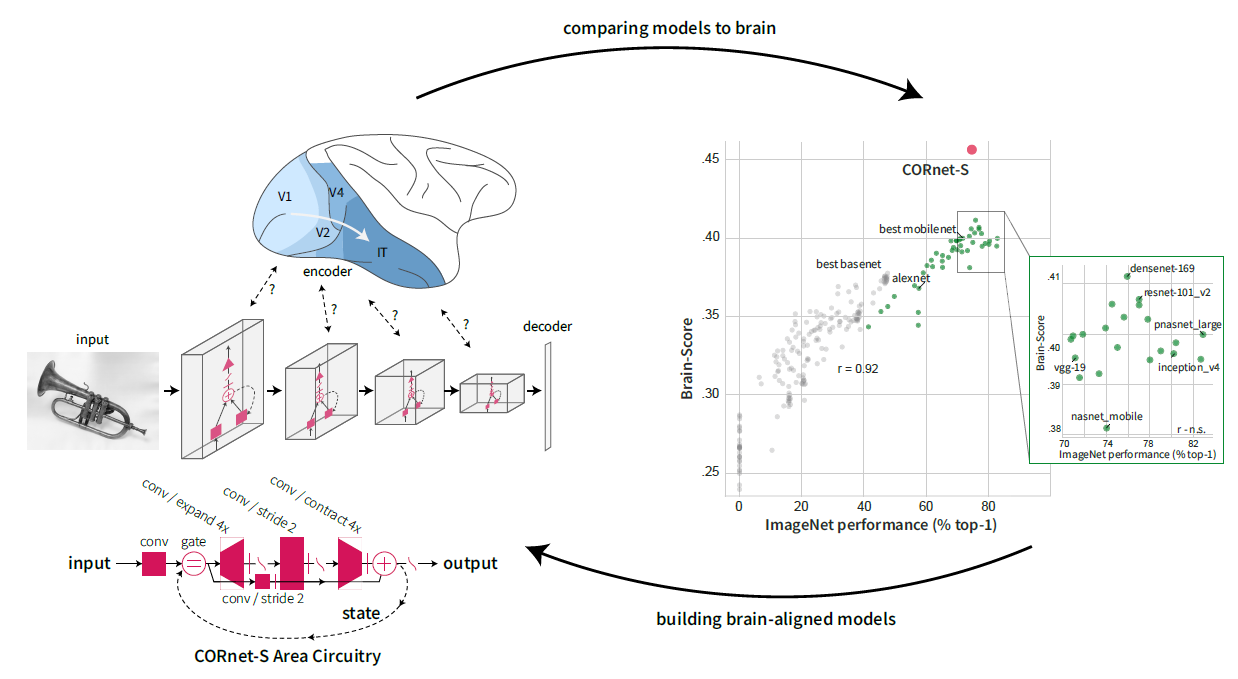
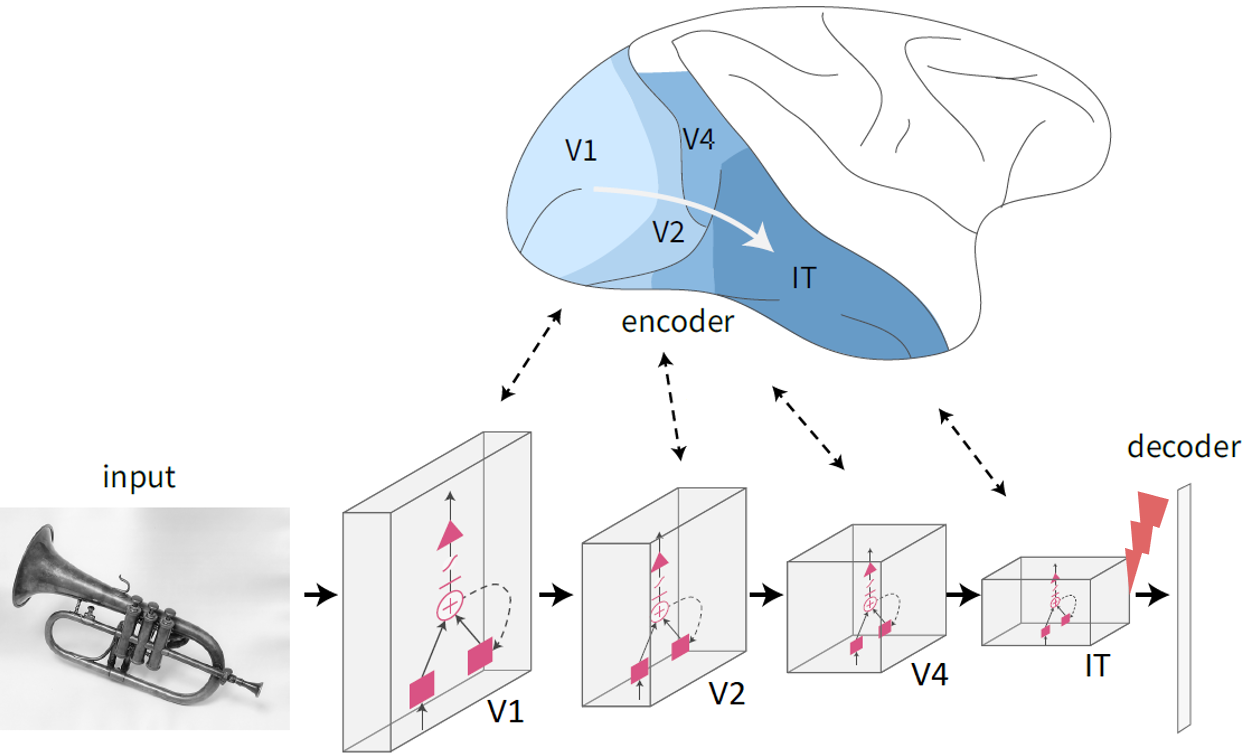
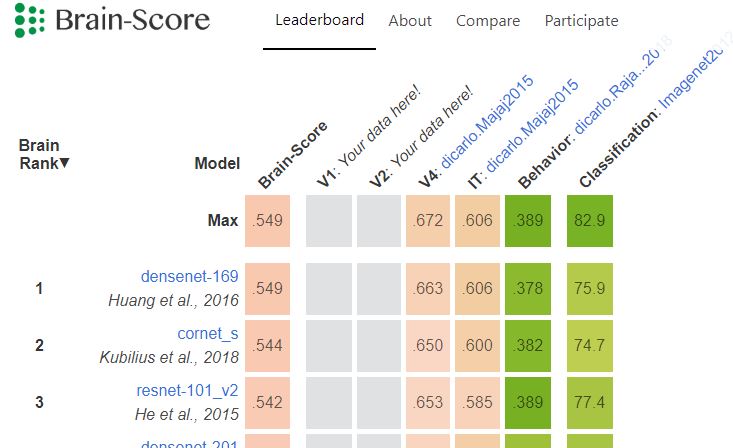
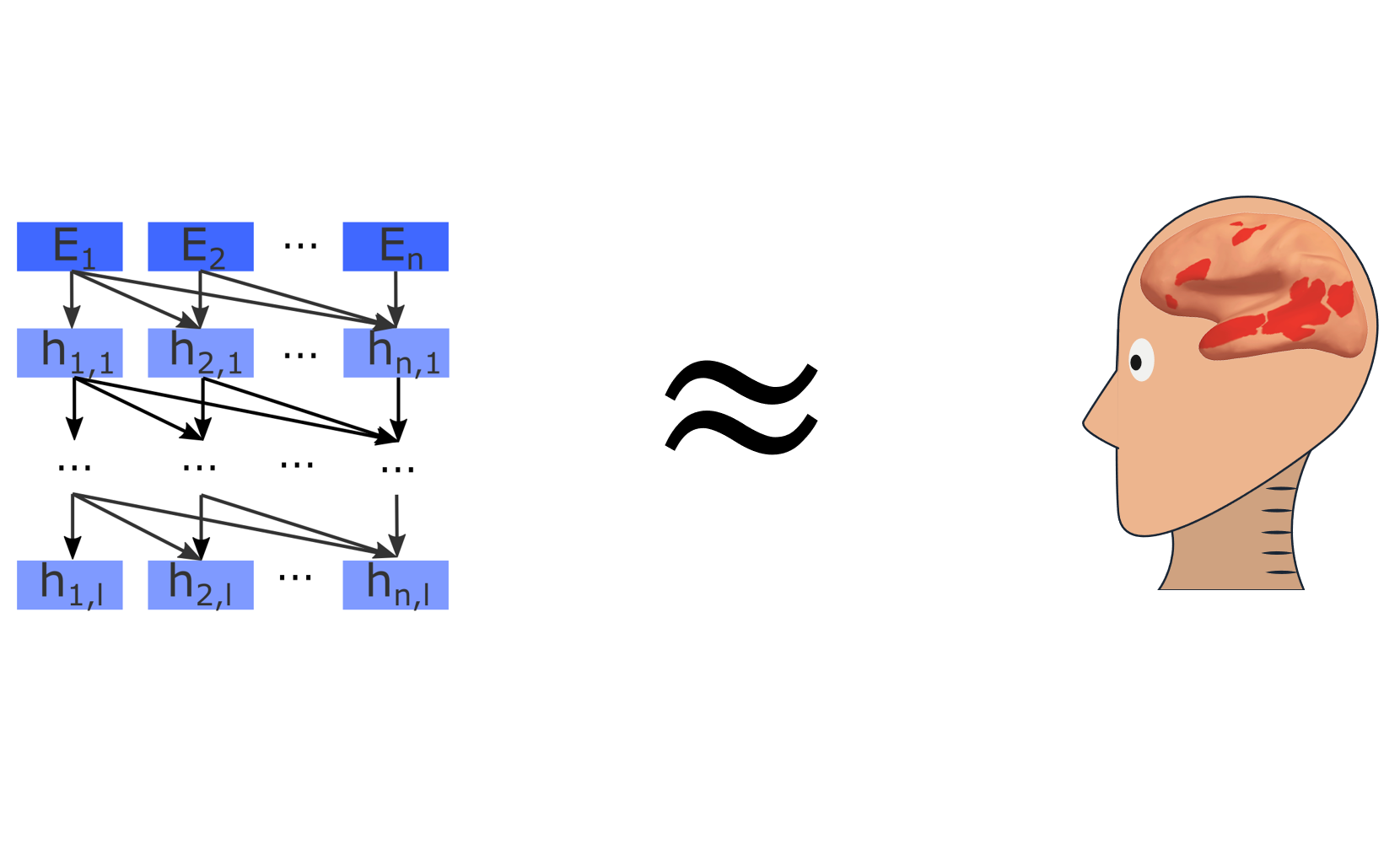
 Computational neuroscience has lately had great success at modeling perception with ANNs – but it has been unclear if this approach translates to higher cognitive systems. We made some exciting progress in modeling human language processing https://www.biorxiv.org/content/10.1101/2020.06.26.174482v1.
Computational neuroscience has lately had great success at modeling perception with ANNs – but it has been unclear if this approach translates to higher cognitive systems. We made some exciting progress in modeling human language processing https://www.biorxiv.org/content/10.1101/2020.06.26.174482v1.
This work is the result of a terrific collaboration with Idan A. Blank, Greta Tuckute, Carina Kauf, Eghbal A. Hosseini, Nancy Kanwisher, Josh Tenenbaum and Ev Fedorenko.
Work by Ev Fedorenko and others has localized the language network as a set of regions that support high-level language processing (e.g. https://www.sciencedirect.com/science/article/pii/S136466131300288X) BUT the actual mechanisms underlying human language processing have remained unknown.
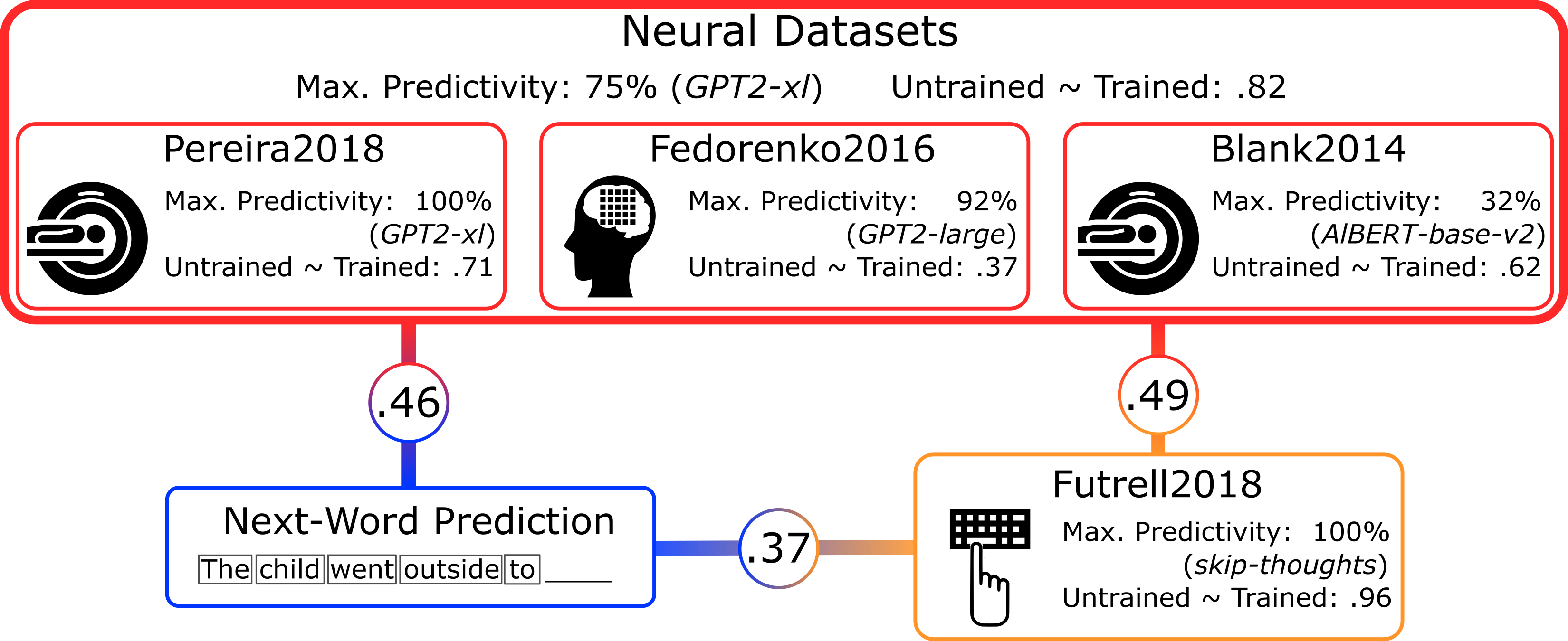
To evaluate model candidates of 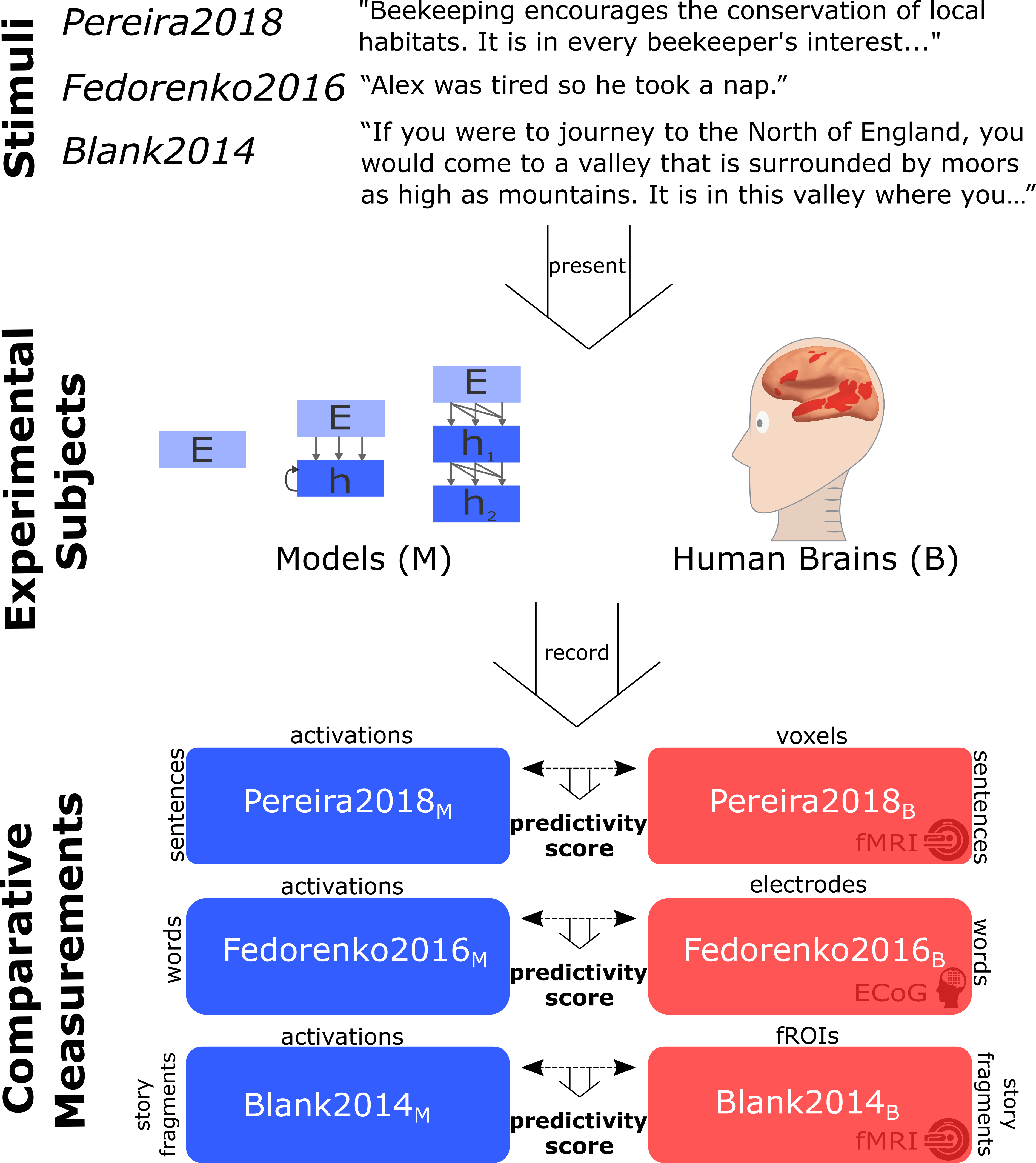 mechanisms, we use previously published human recordings: fMRI activations to short passages (Pereira et al., 2018), ECoG recordings to single words in diverse sentences (Fedorenko et al., 2016), fMRI to story fragments (Blank et al. 2014). More specifically, we present the same stimuli to models that were presented to humans and “record” model activations. We then compute a correlation score of how well the model recordings can predict human recordings with a regression fit on a subset of the stimuli.
mechanisms, we use previously published human recordings: fMRI activations to short passages (Pereira et al., 2018), ECoG recordings to single words in diverse sentences (Fedorenko et al., 2016), fMRI to story fragments (Blank et al. 2014). More specifically, we present the same stimuli to models that were presented to humans and “record” model activations. We then compute a correlation score of how well the model recordings can predict human recordings with a regression fit on a subset of the stimuli.
Since we also want to figure out how close model predictions are to the internal reliability of the data, we extrapolate a ceiling of how well an “infinite number of subjects” could predict individual subjects in the data. Scores are normalized by this estimated ceiling.
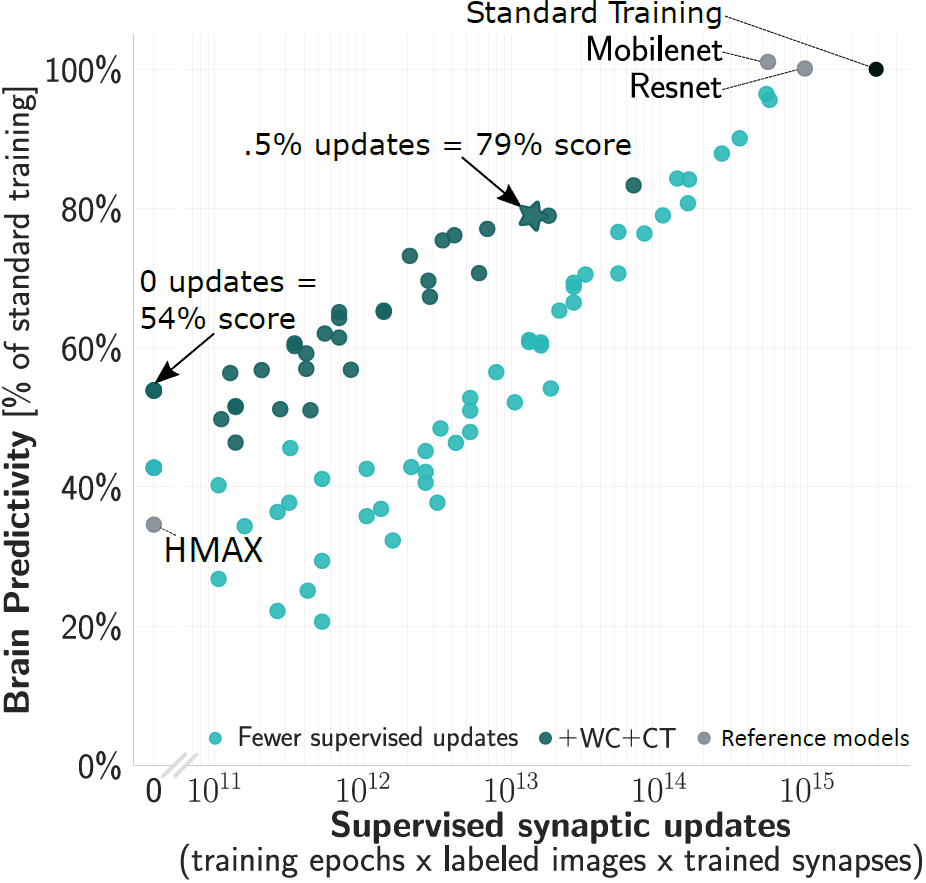
So how well do models actually predict our recordings? We tested 43 diverse language models, incl. embedding, recurrent, and transformer models. Specific models (GPT2-xl) predict some of the data near perfectly, and consistently across datasets. Embeddings like GloVe do not.
The scores of models are further predicted by the task performance of models to predict the next word on the WikiText-2 language modeling dataset (evaluated as perplexity, lower is better) – but NOT by task performance on any of the GLUE benchmarks. 
Since we only care about neurons because they support interesting behaviors, we tested how well models predict human reading times: specific models again do well and their success correlates with 1) their neural scores, and 2) their performance on the next-word prediction task.
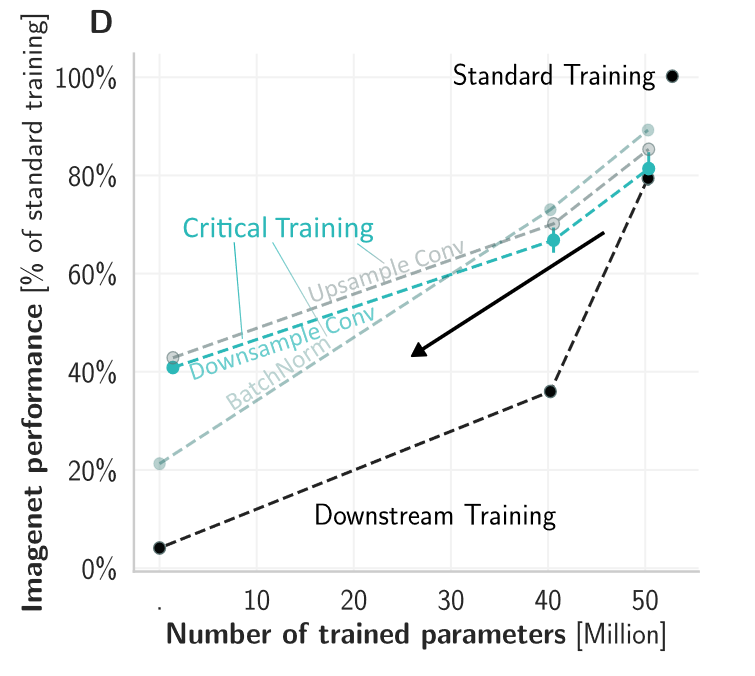
We also explored the relative contributions to brain predictivity of two different aspects of model design: network architecture and training experience, ~akin to evolutionary and learning-based optimization. (see also this recent work). Intrinsic architectural properties (like size and directionality) in some models already yield representational spaces that – without any training – reliably predict brain activity. These untrained scores predict scores after training. While deep learning is mostly focused on the learning part, architecture alone works surprisingly well even on the next-word prediction task. Critically for the brain datasets, a random embedding with the same number of features as GPT2-xl does not yield reliable predictions.
 Summary: 1) specific models accurately predict human language data; 2) their neural predictivity is correlated with task performance to predict the next word, 3) and with their ability to predict human reading times; 4) architecture alone already yields reasonable scores. These results suggest that predicting future inputs may shape human language processing, and they enable using ANNs as embodied hypotheses of brain mechanisms. To fuel future generations of neurally plausible models, we will soon release all our code and data.
Summary: 1) specific models accurately predict human language data; 2) their neural predictivity is correlated with task performance to predict the next word, 3) and with their ability to predict human reading times; 4) architecture alone already yields reasonable scores. These results suggest that predicting future inputs may shape human language processing, and they enable using ANNs as embodied hypotheses of brain mechanisms. To fuel future generations of neurally plausible models, we will soon release all our code and data.

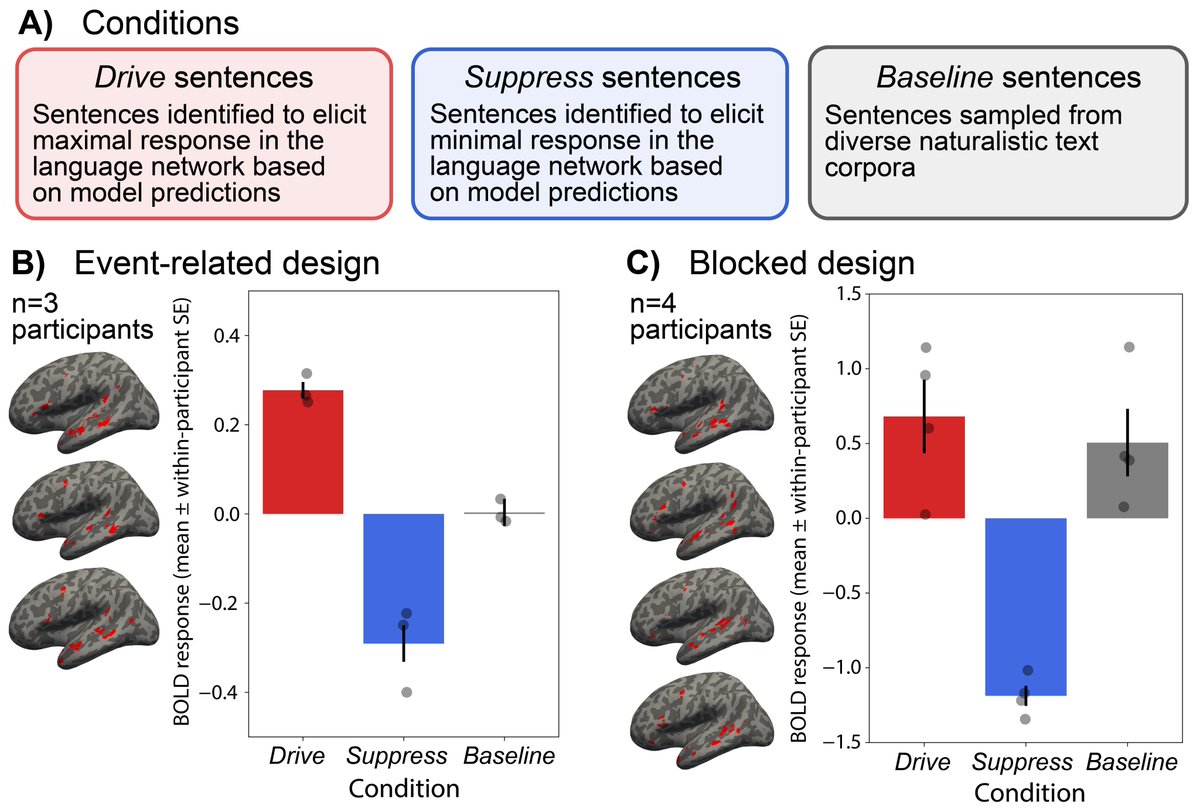
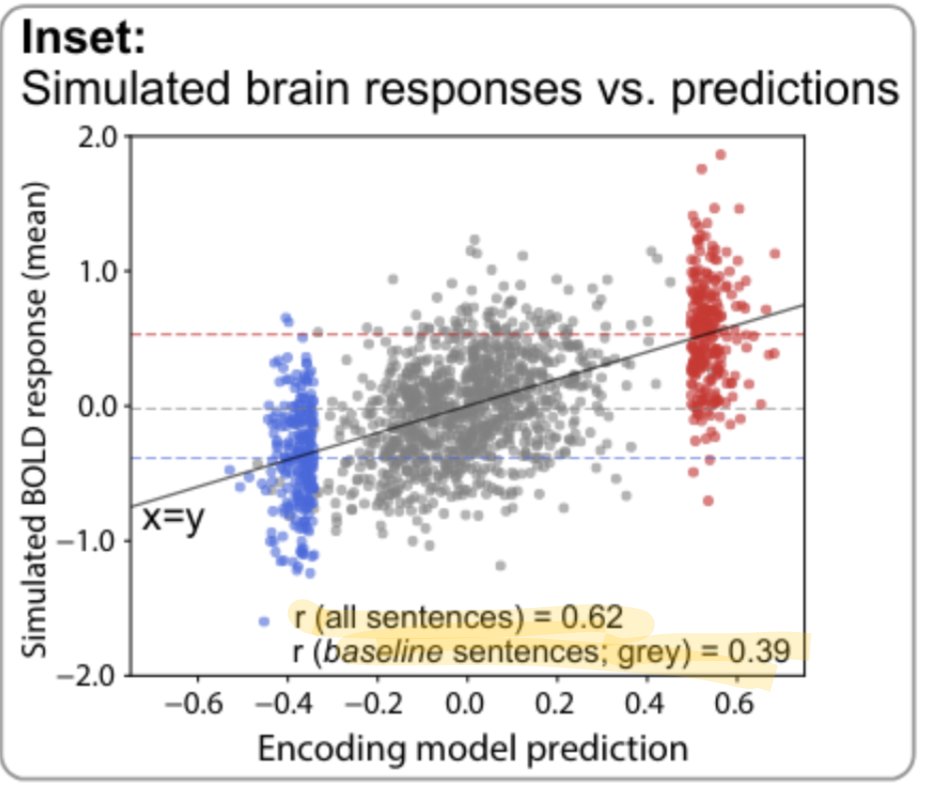 A subtle finding in this work that I find really interesting:
A subtle finding in this work that I find really interesting: