
Certain ANNs are surprisingly good models of primate vision, but require millions of supervised synaptic updates — this unbiological development has been the recent focus of many discussions in neuroscience. Is all this training really necessary? We approach this in new work https://www.biorxiv.org/content/10.1101/2020.06.08.140111v1.
Neuroscientists have argued for innate structure with only thin learning on top, i.e. where structure the genome dictates brain connectivity and is leveraged for rapid experience-dependent development. We took first steps at this with more brain-like neural networks.
with only thin learning on top, i.e. where structure the genome dictates brain connectivity and is leveraged for rapid experience-dependent development. We took first steps at this with more brain-like neural networks.
We started from CORnet-S, the current top model on neural and behavioral benchmarks in Brain-Score.org. We first found that variants of this model which are trained for only 2% of supervised updates (epochs x images) already achieve 80% of the trained model’s score.
Even without any updates, the models’ brain predictivities are well above chance. Examining this “at-birth” synaptic connectivity and improving it with a new method “Weight Compression”, we can reach 54% without any training at all
However, to be more brain-lik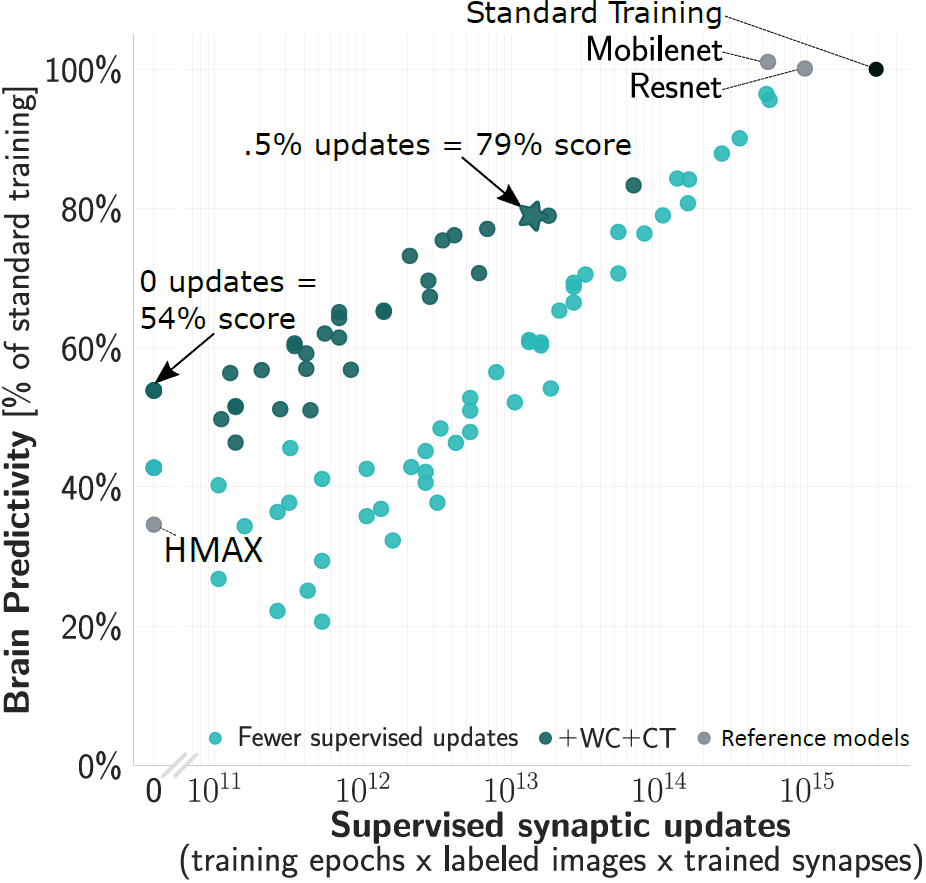 e we require at least some training — but ideally this would not change millions of synapses requiring precise machinery to coordinate the updates. By training only critical down-sampling layers, we achieve 80% when updating only 5% of synapses.
e we require at least some training — but ideally this would not change millions of synapses requiring precise machinery to coordinate the updates. By training only critical down-sampling layers, we achieve 80% when updating only 5% of synapses.
Applying these three strategies in combination (reducing supervised epochs x images + improved at-birth connectivity + reducing synaptic updates), we achieve ~80% of a fully trained model’s brain predictivity with two orders of magnitude fewer supervised synaptic updates.
Taking a step back, we think these are first steps to model not just primate adult visual processing during inference, but also how the system is wired up from an evolutionary birth state encoded in the genome and by developmental update rules. Lots more work to do!